1. Intro
이전 포스트에서 판례 목록 전체를 불러와 csv파일로 저장했다. 이 데이터를 기반으로 이제 판례 전문 데이터를 불러와 txt파일로 저장하고자 한다.
import pandas as pd
import xml.etree.ElementTree as ET
from urllib.request import urlopen
from tqdm import trange
import re
import os우선 필요한 라이브러리를 Import 하고 시작하도록 하겠다
2. 구현
이전 포스트에서 만들어냈던 csv파일에는 ['판례일련번호', '사건명', '사건번호', '선고일자', '법원명', '사건종류명', '사건종류코드', '판결유형', '선고', '판례상세링크'] 정보가 들어있다. 이중 판례 상세링크를 통해 판례 전문을 쉽게 불러올 수 있다.
url = "https://www.law.go.kr"
link = case_list.loc[i]['판례상세링크'].replace('HTML', 'XML')
url += link기본값이 HTML형식인데, XML형식이 더 빠르기 때문에, HTML을 XML로 대체해준다. 그 후 이 둘을 합쳐 URL을 만든다.
response = urlopen(url).read()
xtree = ET.fromstring(response)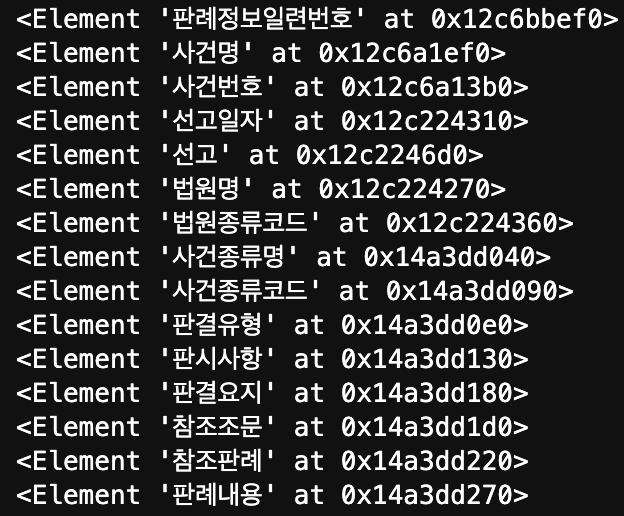
위 URL에 담겨 있는 정보는 다음과 같다.이중 판시사항부터 판례내용까지만 추출하면 된다. 다른 정보들은 이미 csv파일에 담겨있거나, 불필요한 내용이기 때문이다.

문제는 HTML태그가 다음과 같이 뒤섞여있다는 것이다. 위 정도면 괜찮지않나? 싶을 수 있는데,,

참조 판례 또는 조문이 존재하는 경우 위와 같이 엄청난 태그들이 뒤섞여있기 때문에, 태그를 삭제해줘야 한다. 뭐 사실 별 문제는 아니다.
def remove_tag(content):
cleaned_text = re.sub('<.*?>', '', content)
return cleaned_text정규표현식으로 간단하게 없애줄 수 있다.

file = './판례/' + content + '/' + xtree.find('판례정보일련번호').text + '.txt'
with open(file, 'w') as c:
c.write(text)
c.close()HTML 태그들까지 깔끔하게 지워준 후, 판시사항부터 판례용까지 txt파일로 작성해준다. 여러 내용들을 각각의 폴더에 저장해줬으며, 파일명은 판례정보일련번호.txt로 지정해줬다.

3. 전체 코드
import pandas as pd
import xml.etree.ElementTree as ET
from urllib.request import urlopen
from tqdm import trange
import re
import os
case_list = pd.read_csv('./cases.csv')
contents = ['판시사항', '판결요지', '참조조문', '참조판례', '판례내용']
def remove_tag(content):
cleaned_text = re.sub('<.*?>', '', content)
return cleaned_text
for content in contents:
os.makedirs('./판례/{}'.format(content), exist_ok=True)
for i in trange(len(case_list)):
url = "https://www.law.go.kr"
link = case_list.loc[i]['판례상세링크'].replace('HTML', 'XML')
url += link
response = urlopen(url).read()
xtree = ET.fromstring(response)
for content in contents:
text = xtree.find(content).text
# 내용이 존재하지 않는 경우 None 타입이 반환되기 때문에 이를 처리해줌
if text is None:
text = '내용없음'
else:
text = remove_tag(text)
file = './판례/' + content + '/' + xtree.find('판례정보일련번호').text + '.txt'
with open(file, 'w') as c:
c.write(text)
c.close()'기타 > 파이썬' 카테고리의 다른 글
| m1 맥에 konlpy를 설치해보자! (1) | 2021.04.28 |
|---|---|
| 정규표현식을 알아보자!! (0) | 2021.04.27 |
| [잡담] 파이썬의 타입 힌트와 typing, mypy를 알아보자! (0) | 2021.03.21 |
| 2. 판례 목록 수집 - 판례를 크롤링해보자 (6) | 2021.02.28 |
| 1. 국가법률정보 API 사용법 - 판례를 크롤링해보자 (0) | 2021.02.27 |




댓글