1. Intro
정규 표현식(Regular Expressions)은 복잡한 문자열을 처리할 때 사용하는 기법으로, 파이썬만의 고유 문법이 아니라 문자열을 처리하는 모든 곳에서 사용한다. 정규 표현식을 배우는 것은 파이썬을 배우는 것과는 또 다른 영역의 과제이다.
그러면 왜 정규표현식을 사용해야 하는 걸까?
예시로 주민등록번호를 포함하고 있는 텍스트가 있다. 이 텍스트에 포함된 모든 주민등록번호의 뒷자리를 * 문자로 변경해 보자.
우선 정규식을 전혀 모르면 다음과 같은 순서로 프로그램을 작성해야 할 것이다.
- 전체 텍스트를 공백 문자로 나눈다(split).
- 나뉜 단어가 주민등록번호 형식인지 조사한다.
- 단어가 주민등록번호 형식이라면 뒷자리를 *로 변환한다.
- 나뉜 단어를 다시 조립한다.
이를 구현하면 다음과 같다.
data = """
park 800905-1049118
kim 700905-1059119
"""
result = []
for line in data.split("\n"):
word_result = []
for word in line.split(" "):
if len(word) == 14 and word[:6].isdigit() and word[7:].isdigit():
word = word[:6] + "-" + "*******"
word_result.append(word)
result.append(" ".join(word_result))
print("\n".join(result))하지만, 정규표현식을 사용하면 다음과 같은 과정으로 위 과정을 처리해줄 수 있다.
import re
data = """
park 800905-1049118
kim 700905-1059119
"""
pat = re.compile("(\d{6})[-]\d{7}")
print(pat.sub("\g<1>-*******", data))정규 표현식을 사용하면 코드가 상당히 간결해지는 효과를 얻을 수 있다. 문자열 정제 관련 규칙이 복잡하면 복잡할수록 정규식의 효용은 더욱 커지게 될 것이다.
2. 메타 문자
(1) 문자 클래스 []
문자 클래스로 만들어진 정규식은 '[ ] 사이의 문자들과 매치' 라는 의미를 갖는다. 예컨대 정규 표현식이 [abc]라면, 이 표현식의 의미는 'a, b, c 중 한 개의 문자와 매치' 를 뜻한다.
[ ] 안의 두문자 사이에 하이픈을 사용하면, 두 문자 사이의 범위를 의미한다. 예컨대 [a-c]라는 정규 표현식은 [abc]와 동일하다.
문자 클래스 안에는 어떤 문자나 메타 문자도 사용할 수 있다.
(2) Dot( . )
정규 표현식의 Dot( . )메타 문자는 줄바꿈 문자(\n)을 제외한 모든 문자와 매치됨을 의미한다. 예컨대 a.b는 'a + 모든 문자 + b' 라는 의미를 갖는다. 즉 a 와 b 사이에 어떤 문자가 들어가도 모두 매치된다는 의미이다.

주의할 점은 [ . ]의 경우, 즉 문자 클래스 내에 Dot 메타 문자가 사용된 경우에는, 모든 문자라는 의미가 아니고, 문자 그대로 .을 의미한다.
(3) 반복( * )
* 는 * 의 바로 앞에 있는 문자가 0번부터 무한까지(사실 메모리 문제때문에 2억번 정도로 제한된다) 반복될 수 있다는 의미이다.
| 정규식 | 문자열 | Match | 설명 |
| ca*t | ct | Y | a가 0번 반복되어 매치 |
| cat | Y | a가 1번 반복되어 매치 | |
| caaat | Y | a가 3번 반복되어 매치 |
(4) 반복( + )
+ 는 최소 1번 이상 반복될 때 사용된다.
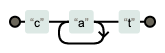
| 정규식 | 문자열 | Match | 설명 |
| ca+t | ct | N | a가 0번 반복되어 매치 안 됨 |
| cat | Y | a가 1번 반복되어 매치 | |
| caaat | Y | a가 3번 반복되어 매치 |
(5) 반복 ({m,n}, ?)
{ } 메타 문자를 사용하면 반복 횟수를 m번부터 n번까지로 제한할 수 있다. ?는 반복은 아니지만, 반복과 비슷한 개념으로, {0, 1}을 의미한다.
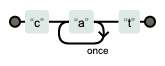
| 정규식 | 문자열 | Match | 설명 |
| ca{2}t | ct | N | a가 0번 반복되어 매치 안 됨 |
| caat | Y | a가 2번 반복되어 매치 | |
| caaat | N | a가 3번 반복되어 매치 안 됨 |
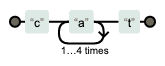
| 정규식 | 문자열 | Match | 설명 |
| ca{2,5}t | ct | N | a가 0번 반복되어 매치 안 됨 |
| caat | Y | a가 2번 반복되어 매치 | |
| caaaat | Y | a가 3번 반복되어 매치 |
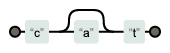
| 정규식 | 문자열 | Match | 설명 |
| ca?t | ct | Y | a가 0번 반복되어 매치 |
| cat | Y | a가 1번 반복되어 매치 | |
| caaat | N | a가 3번 반복되어 매치 안 됨 |
(6) |
| 메타 문자는 or과 동일한 의미로 사용된다.
p = re.compile(r'Python|JAVA')
m = p.match('JAVA')
print(m)
> <re.Match object; span=(0, 4), match='JAVA'>(7) ^
^ 메타 문자는 문자열의 맨 처음과 일치함을 의미한다.
p = re.compile(r'^Python')
m1 = p.search('Python')
m2 = p.search('3 Python')
print(m1, m2)
> <re.Match object; span=(0, 6), match='Python'> None(8) $
$ 메타 문자는 ^ 메타 문자와는 반대로, 문자열의 끝과 매치함을 의미한다.
p = re.compile(r'Python$')
m1 = p.search('Python is easier than JAVA')
m2 = p.search('JAVA is easier than Python')
print(m1, m2)
> None <re.Match object; span=(20, 26), match='Python'>(9) \b
\b 는 단어 구분자이다. 보통 단어는 whitespace에 의해 구분된다.
p = re.compile(r'\bclass\b')
m1 = p.search('no class at all')
m2 = p.search('declassification')
print(m1, m2)
> <re.Match object; span=(3, 8), match='class'> None(10) \B
\B 메타 문자는 \b 메타 문자의 반대이다. 즉 whitespace로 구분된 단어가 아닌 경우에만 매치된다.
p = re.compile(r'\Bclass\B')
m1 = p.search('no class at all')
m2 = p.search('declassification')
print(m1, m2)
> None <re.Match object; span=(2, 7), match='class'>
3. 정규식을 이용한 문자열 검색
파이썬의 re 모듈을 이용해 문자열 검색을 수행해보도록 하자. 컴파일된 패턴 객체는 다음과 같은 메서드를 제공한다.
| Method | 설명 |
| match() | 문자열의 처음부터 정규식과 매치되는지 조사한다. |
| search() | 문자열 전체를 검색하여 정규식과 매치되는지 조사한다. |
| findall() | 정규식과 매치되는 모든 문자열을 리스트로 반환한다. |
| finditer() | 정규식과 매치되는 모든 문자열을, 반복 가능한 객체로 돌려준다. |
import re
p = re.compile('[a-z]+')(1) match
m = p.match('python')
print(m)
> <re.Match object; span=(0, 6), match='python'>python 문자열은 정규식에 부합하므로 match객체를 반환한다.
m = p.match('3 python')
print(m)
> None3 python 문자열의 경우, 정규식에 부합하지 않으므로, None을 반환한다. match의 결과로 match 또는 None을 반환하기 때문에, 파이썬 정규식 프로그램은 보통 다음과 같은 흐름으로 작성된다.
m = p.match('string')
if m:
print('Match found:', m.group())
else:
print('No Match')
> Match found: string(2) search
m = p.search('python')
print(m)
> <re.Match object; span=(0, 6), match='python'>match 메서드와 동일하게 매치된다. 그런데,
m = p.search('3 python')
print(m)
> <re.Match object; span=(2, 8), match='python'>3 python 문자열의 경우 match와 조금 다르다. match의 경우 문자열의 처음부터 검색하지만, search의 경우 문자열 전체를 대상으로 검색하기 때문에, 3이후의 python 문자열과 매칭된다.
(3) findall
result = p.findall("life is too short")
print(result)
> ['life', 'is', 'too', 'short']문자열에서 정규표현식과 매칭되는 단어를 리스트로 반환한다.
(4) finditer
result = p.finditer("life is too short")
print(result)
for rs in result: print(rs)
> <callable_iterator object at 0x7fbd3960bf10>
<re.Match object; span=(0, 4), match='life'>
<re.Match object; span=(5, 7), match='is'>
<re.Match object; span=(8, 11), match='too'>
<re.Match object; span=(12, 17), match='short'>findall과 큰 차이는 없지만, 반환되는 값이 iterator object이다.
4. match 객체
match 메서드와 search 메서드를 수행하면 match 객체를 반환한다. 문자열 검색을 수행하면 어떤 문자열이 매치되었는지, 매치된 문자열의 인덱스는 어디부터 어디까지인지를 알고 싶을 것이다. match 객체의 메서드를 활용하면 위 정보들을 찾을 수 있다.
| method | 설명 |
| group() | 매치된 문자열을 반환한다. |
| start() | 매치된 문자열의 start 위치를 반환한다. |
| end() | 매치된 문자열의 end 위치를 반환한다. |
| span() | 매치된 문자열의 (start, end) 튜플을 반환한다. |
m = p.match('python')
print(m.group())
print(m.start())
print(m.end())
print(m.span())
> python
0
6
(0, 6)match 메서드를 사용하면 언제나 문자열의 시작부터 조사하기 때문에, start의 결과값은 항상 0일 수밖에 없다. search 메서드를 사용하면 값이 다르게 나올 것이다.
m = p.search('3 python')
print(m.start())
> 2
5. 컴파일 옵션
정규식을 컴파일할 때 여러 옵션을 적용할 수 있다.
(1) DOTALL, S
' . ' 메타 문자는 줄바꿈 문자(\n)을 제외한 모든 문자와 매치된다. 만일 \n 문자도 포함하여 매치하고 싶으면 re.DOTALL, re.S 옵션을 사용해 정규식을 컴파일하면 된다.
p1 = re.compile('a.b')
p2 = re.compile('a.b', re.DOTALL)
print(p1.match('a\nb'), p2.match('a\nb'))
> None <re.Match object; span=(0, 3), match='a\nb'>p1에 매치를 시키면 None을 반환하고, p2를 매치시키면 매치된 결과를 반환한다. re.DOTALL 옵션은 여러 줄로 이루어진 문자열에서 \n 에 상관없이 검색을 수행할 때 많이 사용된다.
(2) INGNORECASE, I
re.IGNORENCASE, re.I 옵션은 대소문자 구별 없이 매치를 수행할 때 사용하는 옵션이다.
p1 = re.compile('[a-z]+')
p2 = re.compile('[a-z]+', re.IGNORECASE)
print(p1.match('ABC'), p2.match('ABC'))
> None <re.Match object; span=(0, 3), match='ABC'>(3) MULTILINE, M
re.MULTILINE, re.M 옵션은 ^, $와 연관된 옵션이다. ^ 메타문자는 문자열의 처음을, $ 메타문자는 문자열의 마지막을 의미한다. 하지만 ^ 메타문자를 문자열 전체의 처음이 아니라, 각 라인의 처음으로 인식시키고 싶은 경우가 있을 수도 있다. 이 때 사용하는 옵션이 re.MULTILINE, re.M 이다.
p1 = re.compile("^python\s\w+")
p2 = re.compile("^python\s\w+", re.MULTILINE)
data = """python one
life is too short
python two
you need python
python three"""
print(p1.findall(data), p2.findall(data))
> ['python one'] ['python one', 'python two', 'python three']쉽게 말해 ^, $ 메타문자를 각 문자열의 각 줄마다 적용해주는 것이라고 생각하면 된다.
(4) VERBOSE, X
정규식이 복잡해지면 코드의 가독성이 매우 떨어진다. re.VERBOSE, re.X 옵션은 정규표현식에 주석을 첨가할 수 있도록 한다.
charref = re.compile(r'&[#](0[0-7]+|[0-9]+|x[0-9a-fA-F]+);')
charref = re.compile(r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
""", re.VERBOSE)위 예를 비교해보면 두 객체 모두 동일한 역할을 수행한다. 하지만 두 번째처럼 주석을 적고 여러 줄로 표현하는 것이 가독상이 훨씬 좋다. re.VERBOSE 옵션을 적용하면 문자열에 사용된 whitespace는 컴파일할 때 제거되고, 줄 단위로 주석문을 작성할 수 있게 된다.
6. 백슬래시 문제
정규표현식을 파이썬에서 사용할 때 백슬래시 문자가 혼란을 야기한다. 예컨대 '\section' 문자열을 찾기 위한 정규식을 만든다고 가정해보자.
p = re.compile('\\section')\ 문자가 문자열 자체임을 알려주기 위해 \\ 를 통해 이스케이프 처리를 해줘야 한다. 그러면 '\\section' 문자열의 정규표현식은 \\\\section이고 뭐 쭉쭉 늘어나게 될 것이다. 이러한 문제를 해결하기 위해 파이썬 정규식에는 raw string 규칙이 생겨나게 되었다.
p = re.compile(r'\section')이처럼 string 앞에 r을 삽입해주면 \ 1개만으로 2개를 쓴 것과 동일한 의미를 갖게 된다.
7. 그루핑
특정 문자열이 계속해서 반복되는지 조사하는 정규식을 작성할 때 그루핑을 이용해 정규표현식을 작성한다.
p = re.compile('(ABC)+')
m = p.search('ABCABCABC OK?')
print(m)
> <re.Match object; span=(0, 9), match='ABCABCABC'>
8. 문자열 바꾸기(sub)
sub 메서드는 정규식과 매치되는 부분을 다른 문자로 바꿀 수 있다.
p = re.compile('(blue|white|red)')
m = p.sub('color', 'blue socks and red shoes')
print(m)
> color socks and color shoes
'기타 > 파이썬' 카테고리의 다른 글
| m1 맥에 konlpy를 설치해보자! (1) | 2021.04.28 |
|---|---|
| [잡담] 파이썬의 타입 힌트와 typing, mypy를 알아보자! (0) | 2021.03.21 |
| 3. 판례 전문 txt파일로 저장하기 - 판례를 크롤링해보자 (1) | 2021.03.01 |
| 2. 판례 목록 수집 - 판례를 크롤링해보자 (6) | 2021.02.28 |
| 1. 국가법률정보 API 사용법 - 판례를 크롤링해보자 (0) | 2021.02.27 |




댓글